
Bill’s Reaper Hotkeys — With Screenshots to Show UI When Applicable
First Generation, Second Generation, and Third Generation Note Taking Apps
Use the “frame” command in Ruby debugger: example & explanation
How to change Google Ad Campaign Networks: Video
If software businesses were castles
Locale-specific pure Javascript first day of week function
Cracking open the development process
imho pretty crazy that I can paste a dynamically updating look at my entire programming career since adopting git
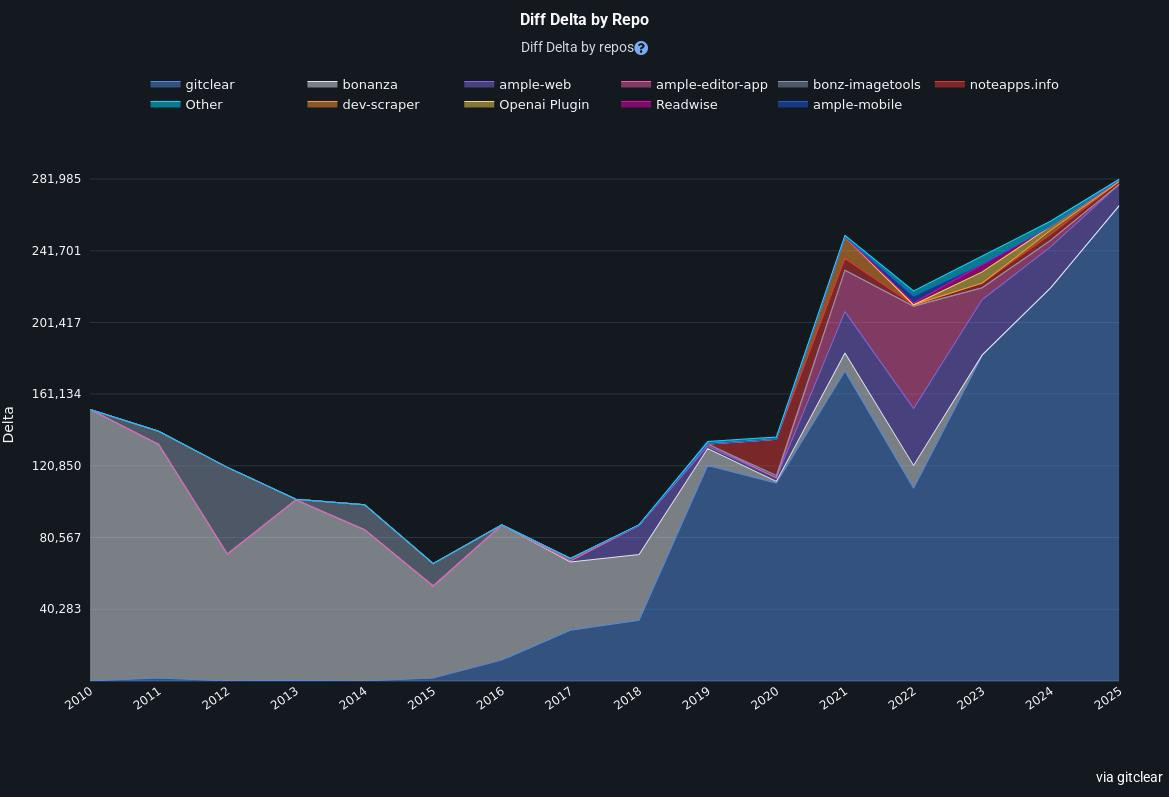
To be determined: whether other devs are curious how their engagement with the code on a year-to-year basis varies? As evidenced by my Line Impact since starting GitClear (2017), I’ve gotten more engaged with every year I get to see my LI. Another small vote for the notion that what’s measured improves.
Do many devs want to challenge themselves to be more focused and make more of a dent in their projects? Very difficult to predict.
Recording screencast videos: a novice’s guide to best 2021 macOS software
Seattle’s Harborview Hospital Covid Visitor Policy
